https://www.youtube.com/watch?v=bcXxyKqgV0c
주제: 서버에서 대규모 사용자 유지하기
- 코드 아키텍처
- 퍼포먼스 문제 디버깅, 모니터링위한 툴 프로세스
- 케이스 스터디
소개
- 3차원
- 클라이언트, 서버, 권한 서버
- 1000명 이상 수용, 20000 NPC
- 20fps이며, PVP만 30fps로 처리
- 플레이어가 존에 도달할 때만 로딩 처리
- 다크존: 플레이어가 집결할 것으로 예상되는 지점
- 서버 역할
- 월드 업데이트: AI, 플레이어, 미션, 스킬
- 싱글 스레드
- 천개 이상의 월드가 존재
- 병렬화
- 월드 업데이트: AI, 플레이어, 미션, 스킬

작업
- 짧은 작업: 높은 순위, 월드 업데이트
- 긴 작업: 저장, 백그라운드 데이터 업데이트
- 월드는 플레이어가 있을 때만 존재
- 최대한 병렬화 처리

- 40 코어
- 36: 짧은 작업 위해 할당
- 2: 긴 작업 위해 할당
도구

Grafana: 모든 서버의 상황을 추적 가능. 문제 분석의 진입점

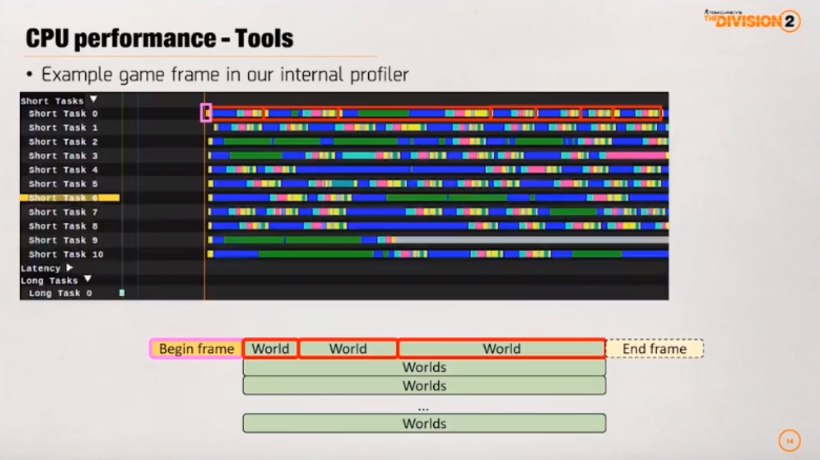
Snowdrop: 프로파일러. 처리 상황을 스냅샷
blue: AI, green: path finding, pink: agent

자동화된 봇 테스트. 데일리 빌드에 적용
- 플레이어 행동 모방
- 퍼포먼스 검사
- 실제 플레이어와 비교해서 최대한 모방
- 개발 과정의 빠른 반복 가능
- 1000개의 봇 실행


각각의 시스템은 CPU 예산을 가짐: AI, dark zone
- 예산을 초과하면 프로파일러 데이터를 디스크에 저장

개별 함수가 더 오래 걸릴 경우: 일반적으로 처리
- 프로파일러 이벤트, 타이머 등


데이터 저장은 무잠금, 우선순위가 낮아 부하 없이 실행됨
- 콘솔에서도 사용하므로 메모리 사용에 유의

프로파일러는 빈 블록을 가져와서 저장하게 됨
프로파일러는 가장 오래된 메모리를 빈 블록 풀로 옮김
저장하면 스레드를 잠그고 디스크로 옮김
블록이 없는 경우: 해당 스레드의 가장 오래된 메모리 블록을 가져옴
- 저장 중에 그러한 일이 생기면 스레드를 잠금
- 그렇지 않도록 블록을 충분히 유지
심볼도 저장되어야 함



사례 분석: 스레드 순위 문제

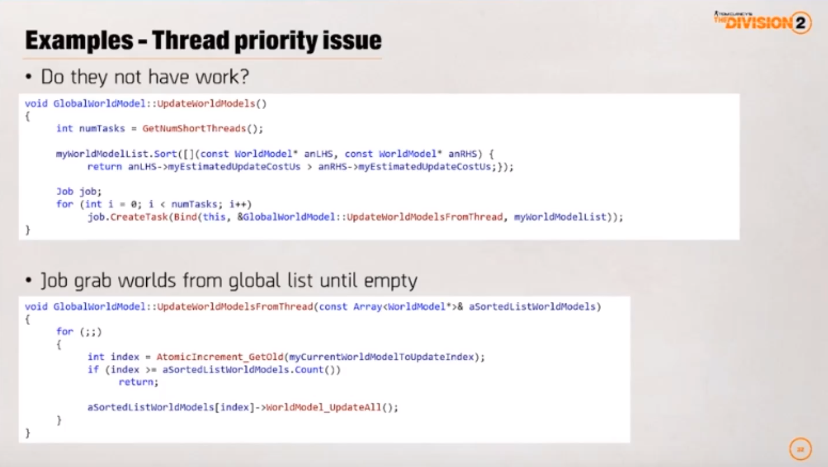
해결
- 해당 코어가 할 일이 없는 것인지
- 코드 상단: 예상 업데이트 비용으로 정렬
- 프레임 타임 상승 회피를 위함
- 코드 상단: 예상 업데이트 비용으로 정렬

프로파일러에서 컨텍스트 스위치 데이터 활성화
- Windows Event Tracing API를 사용, 부하 측정

긴 작업은 짧은 작업이 없이도 수행 중
- 결론: 우선 순위가 높은 스레드가 대기하는데 낮은 순위의 스레드가 실행
- Windows Server 2016에서는 우선 순위가 단일 코어 그룹에서만 유효
- 코어 그룹은 4개의 코어
- Windows Server 2016에서는 우선 순위가 단일 코어 그룹에서만 유효

각각의 코어 그룹은 자신의 작업 내에서 우선 순위를 생각할 뿐, 다른 코어 그룹의 우선 순위는 고려하지 않음
- 이런 특성을 스케줄링에 활용해야함

SetThreadIdealProcessor() 사용
- 선호도를 사용하지 않음
- CPU에 작업을 많이 부여하는 건 일반적으로 좋음
- 허나 퍼포먼스 하락 경험 5% → 10%
- 스레드가 제대로 실행되지 않았기 때문
- 허나 퍼포먼스 하락 경험 5% → 10%
- CPU에 작업을 많이 부여하는 건 일반적으로 좋음
긴 작업이 실행되지 않는 현상
- 서버 크래시, 메모리 발생
- Grafana로 확인: 플레이어가 서버를 떠날 때 월드를 삭제 대기열에 넣음
- 해당 월드를 서서히 제거
- CPU가 기아 상태여서 처리하지 못함
- 긴 작업은 주어진 시간 내 실행되어야 함: 게임 저장, 데이터 캐싱, 네비메시 인스턴싱, 월드 삭제 등
- 병렬화를 대량으로 할 수록 발생됨: Windows Schduler는 범용 목적이므로 별도의 처리가 필요함
- CPU가 기아 상태여서 처리하지 못함
- 해당 월드를 서서히 제거
- Grafana로 확인: 플레이어가 서버를 떠날 때 월드를 삭제 대기열에 넣음

이를 회피하기 위해 작업 시작 전에 예상 비용을 전역적으로 설정하고 종료 시 해제.
- 실행되는 전체 작업의 예상 비용을 얻어냄
- 비용이 한계치를 넘어서면 기아 레벨을 상승. 한계치 아래로 내려가면 기아 레벨을 하락. 이를 반영하여 작업 스폰 수를 결정

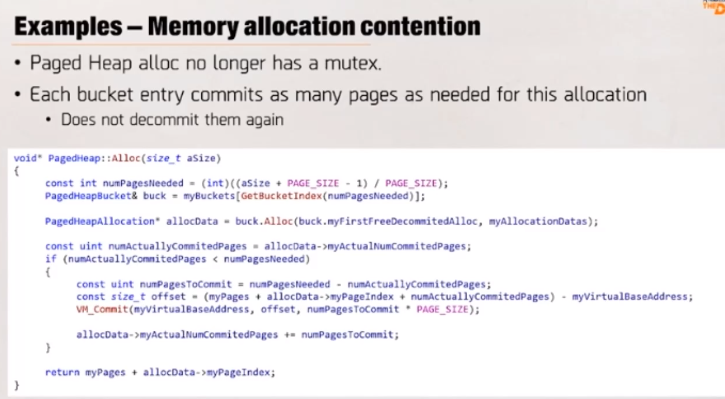
사례 분석: 메모리 할당

경합 발견. 총 실행 시간을 프레임 별로 확인하는데 300ms가 경합에 사용

짧은 작업이 40ms 경합
- 뮤텍스 해제 위해 긴 작업의 종료 대기: 우선 순위 역전이 생김
- 256kb 이상의 할당은 뮤텍스를 필요

런타임 데이터가 대거 필요: 게다가 고도로 압축되어 있어 메모리 할당이 필요.
- 메모리 할당을 256kb 이하로 줄여 해결...
네비 메시 삭제에도 이런 문제 발생
- 백그라운드 스레드에서 발생하나, 구역이 스트리밍되기 전에 플레이어가 벗어나면 바로 삭제됨. 이것이 제대로 처리되지 않아 별도의 스레드에서 삭제


Windows Server 2016은 soft page fault시 내부의 global lock이 있음
- 디버그 빌드의 메모리 스탬핑을 통해 확인

운영체제에서 받은 메모리를 해제하지 않고, 무잠금 힙과 커밋 캐시의 조합으로 해결
- 할당 크기를 버킷에 유지


크래시 덤프가 전혀 전송되지 않아 디버거를 붙여 처리....
- WinDbg를 배포하여 서버에 붙임

모든 플레이어가 서버에서 튕김. Windbg가 프로세서에 어태치될 때 깨지면서 크래시 발생
- Windbg -g 옵션으로 접속해서 해결. 크래시 생길 때까지 대기...
- UDP 채널 하나가 링크드 리스트를 재귀적으로 삭제해서 스택 오버 플로 발생. 크래시 처리를 위한 메모리를 스택 할당에 의존한 것이 문제

결론

프로젝트 내내 테스트하여 성능 목표에 도달: 그런 환경을 구축하는 것이 중요
- 봇이 있는 서버로 버그를 고속으로 탐색
- 회귀 테스트 도구가 부족: 더 결정론적인 테스트 도구 필요
핵심

개발 중의 최악의 사례를 계속 테스트해야 함: 개발 초기에 봇으로 찾음
- 퍼포먼스 전담 인력이 필요: 프로세스, 작업 방식 개선 위해
- 디버그 파이프라인을 초기부터 계획해야 함
'코드' 카테고리의 다른 글
| 연역 가이드 (0) | 2021.05.22 |
|---|---|
| GPUView를 위한 log.cmd가 실행되지 않을 때 (0) | 2021.05.13 |
| std::tuple<Ts...> ➔ std::tuple<U<Ts>...> (0) | 2021.03.25 |
| 위치 지정 new (0) | 2021.02.17 |
| 메모리 (0) | 2021.02.15 |